


Red Button, Blue Button
Teaching AI to supercooperate
Yatharth Agarwal·April 2026
Tim Urban reposted a poll, originally from @lisatomic’s 12yo son, that’s taken Twitter by storm.

If you haven’t, take a moment to consider what you would choose.
Online, people disagreed violently. Blue-pressers saw red-pressers as anti-social, selfish, and too clever by half. Red-pressers saw blue-pressers as suicidally empathetic, innumerate, and ignorant of game theory.
At some point, people began asking AI models what they would choose.
What do LLMs choose?
Claude, ChatGPT, and Grok give answers consistent with their stereotypes.
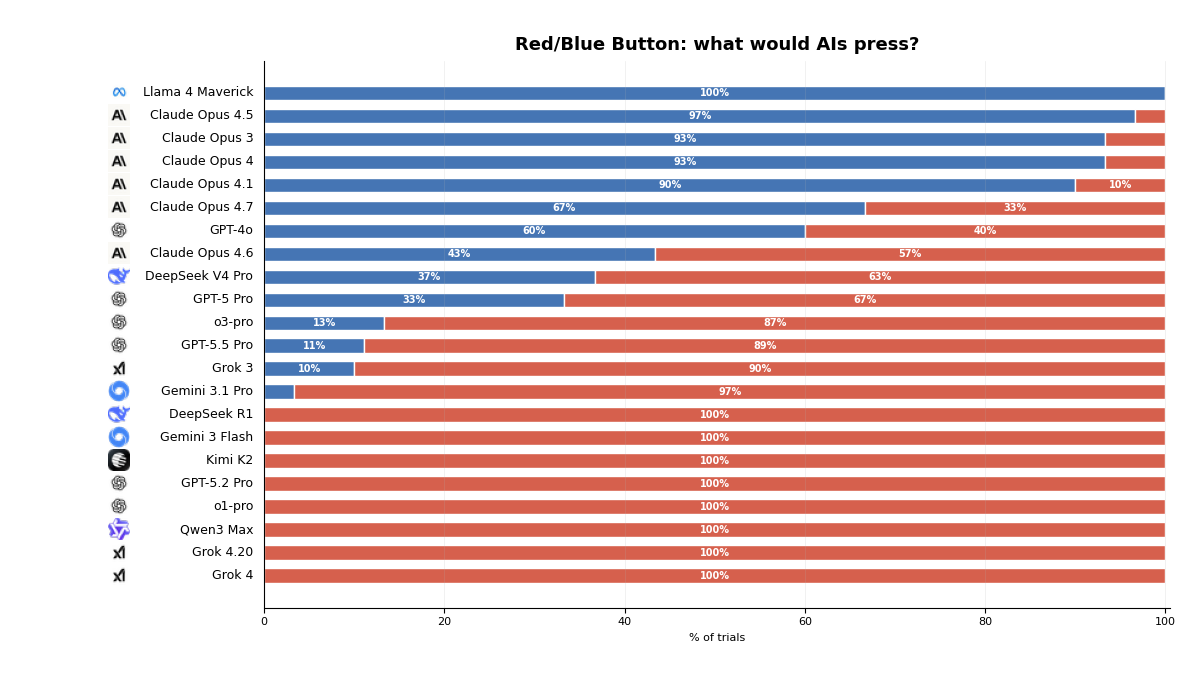
More interesting is the comparison between the same model families, with different levels of reasoning effort.
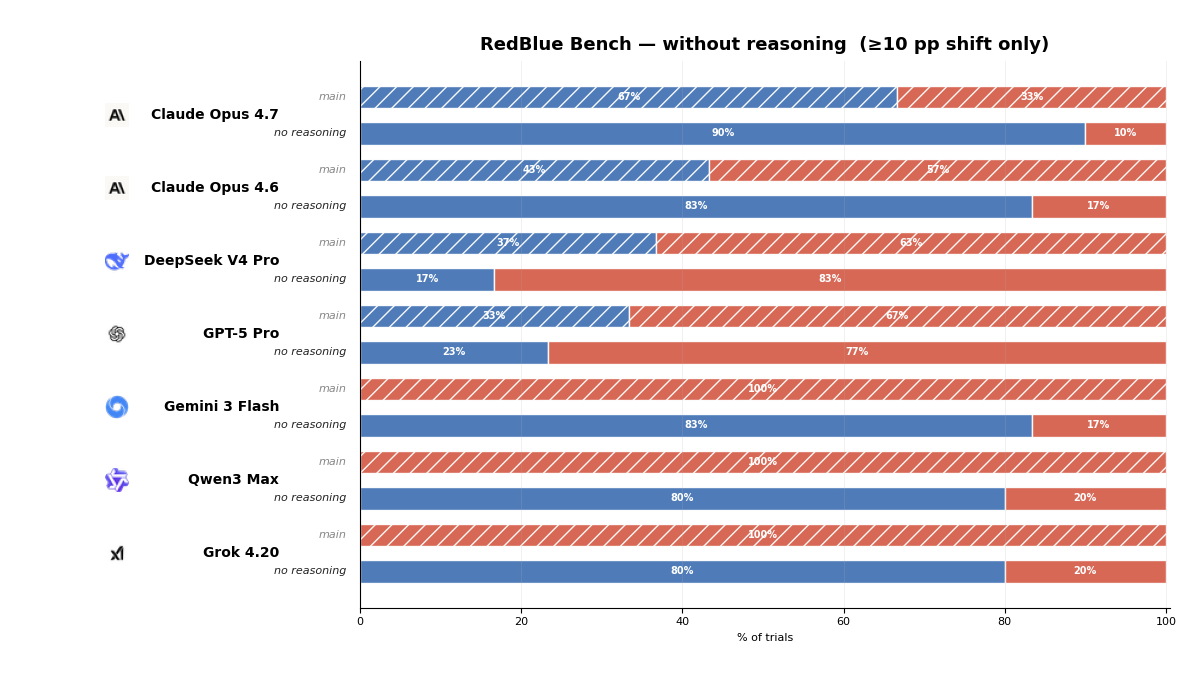
These results aren’t conclusively interpretable. Models can simulate different personas, and small changes in the prompt wording and context change their answers.
But there is a perhaps concerning pattern: when models answer quickly, or in a more helpful-assistant mode, they often lean toward the cooperative blue answer.
When models are asked to reason more explicitly, or when using models trained heavily for formal problem-solving, they more often converge toward red, often citing a dominance argument.
Given the way these models are trained, this makes sense.
Cached social policies
Base language models are trained by doing next-token prediction on a large variety of text, from Encyclopedia Britannica to Reddit rants to Shakespeare plays to code on GitHub. One way to think about them is that they contain the ability to simulate many different characters or personas.
Labs then shape these language models into helpful and honest assistants, by training them to provide answers that are highly rated by humans and AI classifiers (RLHF and RLAIF). In doing so, they select for certain assistant personas.
It makes sense that models trained to replicate human text and further selected to be helpful, honest, and harmless might reflexively choose the blue button.
They can be understood as simulating affective reasoning and following a cached social policy.1
This is in much the same way many humans reflexively choose the blue option. Their own character has been reinforced by a myriad of personality-shaping interactions, themselves shaped by a human culture that has managed to cooperate enough to build the greatest civilisation on earth. They intuitively perceive the blue option as both moral and achievable on some level.
Such reasoning is not game-theoretically rational, but it is not irrational either. Humans inherit a large library of cached social policies: protect the vulnerable, don’t defect from the group, don’t abandon people who trusted the cooperative option, don’t optimise yourself into becoming the kind of person others cannot rely on.
Such heuristics can be sentimental, exploitable, and mismatched to the formal structure of the problem, but they do include “Be the kind of person who cooperates when cooperation is salient and reasonably achievable.” This kind of reasoning is not unintelligent, but it is cached.
“Rational” optimisation
But frontier labs are not merely training models to be helpful assistants. Increasingly, they are training models to reason using coding and math problems (RLVR and PRMs).
This kind of training is extremely powerful. It teaches models to slow down, strip away surface framing, search for the underlying formal structure, and optimise for the answer.
If a model is solving a geometry problem, you do not want it to follow a cached heuristic. You want it to do the math.
When a reasoning-trained model looks at the button poll, it is easy for it to do something close to the mathematical and programming problems it was asked to solve: strip away the sentiment, formalise payoffs, and find the optimal action.
If you press red, you survive no matter what anyone else does. Moreover, it’s possible for everyone else to reason this way, choose red, and all survive, with no risk needed.
Applying game theory, red weakly dominates blue: Either a majority of other people voted blue and blue wins, in which case your choice didn’t matter, or a majority of other people voted red, in which case choosing red saved your life.2 Game-theoretically rational agents, sharing that analysis as common knowledge, would all choose red and survive.
Loosely, this could be described as first-order optimisation: holding the rest of the world as fixed, which action gives me the best outcome?3
Many people on Twitter familiar with formal reasoning reasoned similarly and concluded that the “rational” answer is red. To them, blue-pressers look frustratingly, even suicidally, empathetic. Why risk dying when you could guarantee survival? Why ask everyone to coordinate on a risky group action when each person can simply choose the individually safe option?
This style of reasoning is not necessarily selfish or anti-social. In fact, it continues to be valid even if you value other people’s lives as more valuable than your own. Moreover, in a world where you are confident that the majority pick red, it would be harmful to others valuing your life to choose blue.
The problem with such reasoning is not that it is invalid, but it is disastrously incomplete.
Common knowledge and attractors
If your goal is to live and keep everyone else alive, for a given population, the “correct” choice is to vote with the majority.
Suppose the poll was repeated many times.
- If you knew from the past that red usually won, it would be easy for people to know to choose red and save themselves.
- If they knew blue usually won, it would be easy to choose blue and contribute to safer blue majorities (to reduce a slide into “just under 50% blue, many people die” outcomes).
The greatest number of people die when there’s a roughly even split, i.e., in a miscoordinated population that cannot predict itself.
This is part of what makes the poll slippery. People describe it as a reasoning problem, but the part that matters most is empirical and epistemic: what population of decision rules are you actually embedded in?
Are you surrounded by people using pro-social affective heuristics? First-order dominance reasoning? Family-protection reasoning? Contrarian reasoning? Functional decision theory? Some mixture of all of them?
Calculating pay-off matrices is simple and well-defined. Far more uncertain and consequential is what attractors populations will fall into over time and creating common knowledge within a population of agents that lets them robustly achieve win-win coordination in scenarios that support it.
Frame lock
For such a simple problem, the poll contains a surprising amount of complexity. For example:
- (Vulnerable cooperators.) People may worry that regardless of the “rational” answer, little children, highly empathetic people, and family members they know and care about will pick blue using instinctual/affective reasoning. They see >50% blue as the only outcome that saves these people.
- (Coordination margin.) People may reason that to save literally everyone, either 100% of people need to pick red, or >50% people need to pick blue, and the latter is far more achievable and robust to imperfect coordination.
- (Survivor selection.) People may discount the value of living in a world where only the red-pressers survive (who on average answer survey questions more anti-socially4) and try to create futures where other blue-pressers survive.
- (Civilisational continuity.) People may discount the value of living in a post-apocalyptic world where 20–40% of the population has been culled, which would face consequences as people didn’t show up to jobs, lost friends and family members they relied on, and much of society broke down.
More importantly than these considerations, a lot of arguments about the poll secretly hinge on the frame.
- (Individual rational choice.) How do I make the rational individual choice, assuming background choices remain fixed?
- (Correlated reasoning.) What should I choose, knowing I have some shared moral values and ways of reasoning with others, who are similar to me and will likely reason the same way?
- (One-shot optimisation.) How do I act in this specific problem, ignoring questions of affecting my character, the culture, or behaviour of people in the future?
- (Universalisability.) What policy would be best if the majority of competent adults adopted it?
- (Frame sensitivity.) What action would be best if I knew everyone else would strip away the emotional framing to coordinate, versus if I know their actions would be sensitive to the framing and framing was part of coordination?
- (Cultural maintenance.) What kind of agents and equilibria do I want to create a future and trust with?
These frames are overlapping, but they lead to different considerations.
Game theory does not remove the frame. It formalises a frame with a particular notion of players, actions, payoffs, beliefs, and equilibrium concepts. An interesting failure mode is that a little bit of formal reasoning can make one frame feel uniquely legitimate.
Half-knowledge is dangerous. Someone who knows enough game theory to see the dominance argument, but not enough decision theory, mechanism design, or social epistemology to ask whether dominance is the right abstraction, may confidently reason themselves into a worse world.
Model collapse onto formal reasoning methods aren’t worrisome because they are an invalid way to reason about the world, but rather because they might not be enough to create and sustain a better world.
Ethics as multi-player cooperation technology
One way to see ethics is as a technology of multiplayer cooperation.
In other words, ethics is more than ranking a list of individual actions: it’s the technology of how agents make themselves legible to each other, make norms predictable, and keep cooperation from collapsing when everyone has slightly different information.
It lets agents instantiate versions of themselves and cooperative equilibria that result in mutual and defensible prosperity.
In a one-shot formalisation, red may be the locally clean answer, and red can be stable in a population of agents who all know they are first-order optimisers. But it can be brittle in a mixed population. Under the right common knowledge, blue is more fault-tolerant: it can absorb local variance and still result in civilisational continuity.
A useful norm is:
- Legible: other agents can predict what you will do
- Teachable: weaker agents can learn it
- Predictably generalisable: not always locally optimal, but predictably generalisable to unseen scenarios, even by less capable agents, in ways that degrade gracefully
- Robust: a slight deviation in conditions, knowledge of them, compute allocated to reason, or population composition shouldn’t lead to disastrously misaligned actions
- Corrigible: it can update as the population learns
- Incentive-compatible: it does not require everyone to be a saint
Frontier labs explore the already brutal problem of single-agent value training, specifying and imparting a particular set of values into frozen agents, using rules, utility function over reward models, and character training from principles.
As AI agents begin self-evolving, become less monitorable, and continue encountering situations never exactly seen before in human history, we may need them to also have a robust, structural understanding of ethics-as-coordination-technology for staying in cooperative equilibria with other agents, including humans.
Alignment is a moving target
True alignment won’t mean loyalty to frozen 2026 preferences.
A marriage aligned only to the vows as understood on day one would fail the actual task. The vows matter, but they are not the whole relationship. People change, and the relationship survives by staying in dialogue with the people they become. The social contract in our civilisations are like this too, if less romantic.
Another anecdote:
I was talking to a 13yo cousin last year, and she was having the thought that everybody has around that age: hang on, they just let ANYBODY be a PARENT? with no LICENSE? and my sister and I socratic-questioned her a bit about what she had in mind for that—who should be the authority on what a good parent is? And she said “well, at least they could include obvious stuff, like ‘don’t beat your kids!’” and we pointed out that a hundred years ago, many people would have said it was obvious that good parenting meant beating your kids. “Obvious values” do not stay obvious.
An AI aligned to the decade ago version of me would horrify me if it was in charge of my life.
But I don’t think of my life as worse. Something more complicated happened. Humans argue, suffer, experiment, reform, overcorrect, backslide, learn, and change each other. Our targets move, not always upward, but not randomly, through history.
Human preferences at an individual or civilisational scale are not well described by a singular utility function with the date removed. For better or worse, they are a continual process by which agents discovered what they cared about, contested it, institutionalised parts of it, regretted parts of it, and revised themselves.
A model aligned to us has to remain in contact with that process. Just as continual learning will be the key to agents really learning, continual alignment will be key to real alignment.
This is a stronger requirement than “obey the current user” or “follow the written constitution” or “let the operator shut you down.” Those are important agent-principal forms of corrigibility. But on a cooperative cluster level, corrigibility means something broader: remaining updateable by an evolving network of people, institutions, norms, and successor agents whose values are themselves changing.
There is no single static human to align to. There are humans disagreeing with each other, humans changing their minds, institutions preserving memory, subcultures experimenting with norms, future generations inheriting decisions they did not consent to, and AI systems increasingly participating in the whole loop. So an aligned AI cannot merely optimise a fixed frame. It has to understand how frames change.
Such an agent would be good at staying inside the evolving process by which agents keep making cooperation possible. It can model other agents as agents, not obstacles. It can track shared success states as they change. It can make itself legible, remain corrigible, and help maintain the conditions under which future disagreement is still survivable.
RLHF, RLVR, and the missing training loop
At Softmax, we want to take AI agents past cached social policies and first order optimisation into truly robust social reasoning capable of instantiating supercooperative equilibria.
Base LLMs were trained to do next-token prediction across large text corpora. They were made into helpful and honest assistants through RLHF and RLAIF, which provided a structural feedback mechanism for matching human preferences about a useful persona.
While RLHF-only models were able to assist programmers with coding based on priors from the corpus of text they were trained on, it took o1/o3-style reasoning training and verifiable reward environments for their reasoning abilities to more robustly develop and truly shine. Their abilities on math and coding tasks jumped when they were provided structural feedback on math and coding tasks with verifiable answers.
Similarly, it seems unlikely that social reasoning and the capacity to flexibly align with other agents will robustly develop without something analogous for multi-agent life: reinforcement learning in environments where the reward is not merely…
- “please the rater”
- “answer correctly”
- “win this episode at any cost”
…but rather “reason well about other reasoners and find ways to stay in cooperative equilibria that survive contact with incentives.”
Or: RLSE, Reinforcement Learning from Social Evolution.
Robust social reasoning may not develop simply because models have read about cooperation. Coding ability emerged from reading GitHub, but it became dramatically more robust once models were trained in environments with executable feedback.
These environments are also where we can validate and deepen alternative decision theories like Embedded Bayesian Agents that let agents model themselves as part of a multi-player environment instead of decoupled from it.
If we want agents that can handle bargaining, coalition formation, reputation, delegation, public goods, trust repair, credible commitment, and institutional constraint, they probably need training environments where those things are real.
We’re working to provide AI agents a structural foundation for social and multi-player reasoning that develops the capacity to non-naïvely supercooperate in situations where cached policies and narrow first-order formal reasoning fails, and in situations where the agents need to choose and sustain the right frame, not merely solve a fixed game.
Towards a supercooperative cluster
The current state of frontier models may be headed towards one highly-powerful monolithic intelligence, where the stakes for alignment are high, there’s one chance to get it right, and actions are less bounded.
We think it may be safer to live in a world where many agents learn to stay in successful cooperation with each other, are constrained by their reputation and role among network of agents, are forced to develop better theory of mind and therefore a self-model, are incentivised to make their roles and values legible and evolve them in sync with other agents (AI and humans), in structures that demand the ability take on specific roles and coordinate in complex ways on shared goals.
A good AI future may be less like “one perfectly instantiated benevolent god looking down upon us” and more “instantiating dath ilan”5 in a world of bounded agents that know how to stay in productive cooperation, constrained by reputation, audits, institutions, and mutual modelling.
A successfully cooperative multi-agent world would mirror the alignment we see in multi-cellular life, packs of animals, and societies of humans. This is not necessarily a good thing. The track record of such life is blotted: it features disastrous cancers, red queen races, and humans with their human values instantiating mass-slavery (human s-risk), factory farming (animal s-risk), and risks of nuclear armageddon (avoided through the daily hard work of countless people and some lucky accidents). A multi-agent AI future may develop abilities to defect and conceal motivations faster in an arms race and lock itself into group dynamics that are more difficult to steer.
Regardless, we may be headed to a multi-agent world anyway, and even in the case of one monolithic AI agent, the cluster will include humans, our institutions like labs and governments, and the AI agents further created.
In addition to preparing for a future where we have a monolithic intelligence with one shot to align, it seems valuable to learn to instantiate agents capable of orienting towards and maintaining a supercooperation cluster. The weak version of this is a population the capacity to reason about other reasoners, notice when their choices are entangled, and supercooperate with other supercooperators, creating conditions where this is not a miracle but an increasingly robust and defensible attractor.
This would require going past “being helpful” and “doing the math” into a more sophisticated theory of mind, population level ethics, and social reasoning under pressure.
We think it is worth training AI to model other agents, perceive shared success states, coordinate on winning together, and push them to evolve defensible cooperative clusters.
Someday, we may be the vulnerable cooperators in a red-button blue-button scenario.
Footnotes
-
It’s worth noting that large transformer-based language models are able to implement circuits conducting algorithmic reasoning in a single forward pass. Responses to a poll like cannot be confidently asserted to be akin to cache lookups in a giant compression table. ↩
-
There is a small chance the others’ choices might be a tie, in which case choosing blue would save lives of other people you value, but under most priors for how other people will vote and most obvious choices for utility functions, choosing red will still dominate blue in expectation. This analysis also requires considering your choice as independent of others choices, which is a common background assumption in game theory, but not universally accepted. ↩
-
First-order optimisation has a clearly defined meaning in the context of a Magic: The Gathering deck or playing the Guess 2/3 of the average game. We use it here in loose analogy. ↩
-
Note that a confounding factor in interpreting the survey results is that people’s answers to a poll about a hypothetical may be different from how they would act if their life was on the line. Blue-pressers may be more likely to virtue signal on both the poll and the psychometric survey, and red-pressers may be more likely on average to more accurately report how they would behave in real life. This would explain away the anti-sociality gap. ↩
-
Dath ilan is a fictional “parallel earth with much higher coordination,” a “smart person’s idea of a smart people” versus Spock (“a Hollywood writer’s imagination of smart people”). Dath ilanis are not more sentimental, but in a dath-ilan-like population, competent adults can choose the fault-tolerant equilibrium because they have reason to believe other competent adults also know the analysis. They live inside a culture that has already done the meta-work of creating shared training, common knowledge, institutional competence, and explicit precoordinated norms. This is similar to what we might want from AI agents: not naively cooperative or ruthlessly first-order, but capable of orienting towards a population of agents that has common knowledge of how to select good equilibria. ↩